CODING BFF 架构演进方案
这篇文章来源于我曾经在 CODING 负责构建 BBF 中间服务层时记录总结的演进方案,在数据脱敏之后公开出来,希望给予有类似业务需求的同学或团队一点灵感。
演进背景
在传统的前后端分层设计中,通常是前端(Web/App)直接访问后端服务;而后端方面,随着容器化技术的发展,Monolithic 的架构正逐渐向 Microservices 进行转移,而这种架构下的微服务之间进行相互调用,得到最终的调用结果供前端消费。
在一般业务需求的驱动下(UI 驱动),前端消费的数据常见的情况是跨多个微服务提供的数据,为了减轻 Client 端的网络消耗(HTTP),往往需要 Server 端提供整合数据的能力,以及附加一些针对 UI 的逻辑处理。
源于 Domain-Driven Design 的 Server 端自然与面对 UI Driven 的 Client 端之间有需要协调的部分。特别是针对当时的业务形态:研发规范(Workflow)的场景,在各个其他业务线独立能力的基础上增加自有的逻辑,以及横跨多个业务交互的场景。
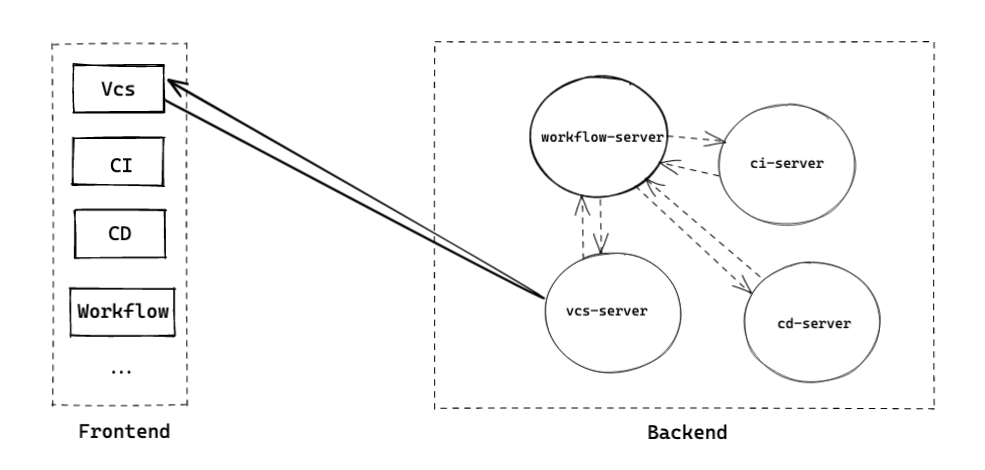
从本质上我们需要让业务的研发工作(FE/BE)更符合 SoC
For Frontend:
- 可定制化根据 UI 的展示数据,对 API 返回的数据进行适当裁剪和整理
- 根据特定业务需求,聚合多个微服务提供数据
- 为微服务之间做转发数据,获得最终业务需要的数据
- 对频繁请求或场景的数据进行缓存
For Backend:
- 微服务架构内部的演进以及微服务的拆分后的治理,减少对前端的影响
- 跨微服务的 API 上升到 BFF,消除业务代码依赖
演进方案
我们可以在前后端架构模型之间添加中间层以解决和满足我们上述的痛点/需求,在业内这层也被叫做 BFF (Backend For Frontend),这里的 For Frontend 代表了前端作为最终消费者的角色,在一般的场景下,这一层由前端团队负责,但收益方是包括前后端的。
加入了 BFF 的前后端架构中,最大的区别就是前端服务不再直接访问后端微服务,而是通过 BFF 层进行访问。从微服务的角度来看,由于有关 UI 逻辑的数据在 BFF 层进行了处理,微服务之间的相互调用更少了。
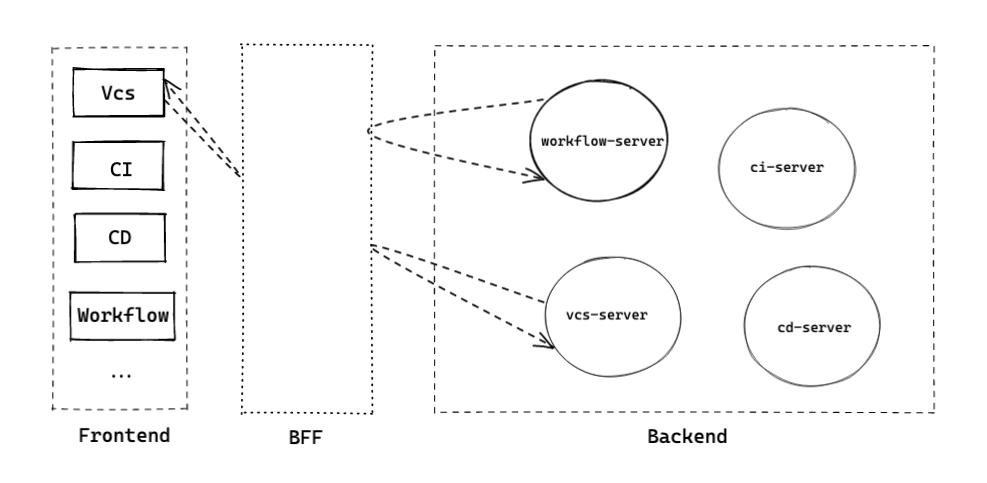
BFF 节点的细分粒度
常见的几种拆分方式
- 端级:以 PC,Mobile 来区分
- 组织架构级
- 业务级:以不同业务主体为拆分方式
以 CODING 的业务和组织架构,我们可以拆分 BFF 为 Vcs-BFF / CI-BFF / CD-BFF 等
如何对接上游前端服务
这里面临常见的技术选型,主要围绕在权衡 RESTful API 和 GraphQL。
在这里我们将选用 GraphQL,并支持 fallback 一些 RESTful API
Why GraphQL?
作为一种 Query Language,GraphQL 具有以下特点:
- 支持精确的数据定制能力。消费者在一个 end point 中自由组合需要的资源,减少不必要的多次请求以及多 API 调用的复杂性
- 代码即文档,所有的 query 以及 mutation 自动生成 schema (文档)
- 无需获取全部的数据集,通过 schema 和 resolver 之间的映射关系,只需要在对应的 resolver 中编写数据的获取逻辑
- 数据的类型系统配合前端,提高开发效率
如何对接下游微服务
对接下游的后端微服务存在这几点问题
- 对接多个不同技术栈的微服务
- 如何管理组织这些调用,以及调用失败的情况
以 RPC 或者 HTTP 等通用协议抹平各技术栈实现的差异。利用一些 async stream 控制库简化异步调用的复杂性,在 BFF 进行调用失败的容错,定制错误信息返回前端。
综合以上的架构图:
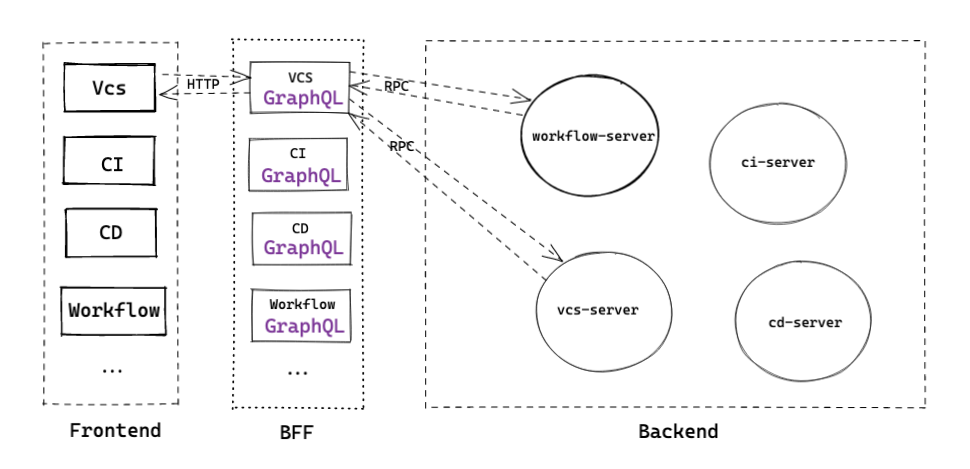
CODING BFF 主要满足了以下功能
- 服务聚合:为前端提供业务数据的聚合点,屏蔽微服务之间复杂的调用链
- 数据清洗:在 BFF 聚合/转发/过滤后端 API 的数据,重新构建符合 UI 驱动模型的数据结构
- 业务隔离:针对每一个独立的业务,都有其专用的 BFF Server 做逻辑处理
- 应用缓存
- 未来:在这层改造进行支持 SSR or hydrate 渲染;支持 react server component
实现路径

服务端 Server
Server 这里采用 Node 开发,原因是考虑业务迭代效率的因素,Client 和 Server 采用统一技术栈,周边生态可复用,支持未来的同构代码/SSR/以及更高能力的混合渲染;以及这层主要承担的职责是网络 I/O bound,不会涉及到大量的 CPU bound,语言层面 Node 可以胜任 BFF 的绝大部分场景
这里使用 Koa 作为 HTTP middleware framework,利用 U 型中间件系统处理响应以及便捷实现后置处理逻辑,借助 Co 结合 Generator,增强异步控制流的能力;Koa 没有捆绑任何 middleware(对比 Express),在这里我们将根据需求使用一些中间件。
由于采用 GraphQL 作为 Client 和 Server 交互的方式,我们可能需要一个支持 GraphQLSpec 的解决方案,比如 Apollo,当然也可以直接使用官方的 graphql 来解决,解决方案层出不穷,其实在这里我们只看重两个点:
- 可执行的 GraphQL Schema 和 Resolver,结合响应查询
- 接受 GraphQL Request 的能力,结合 Schema 返回结果的逻辑
在这里我们将使用 Koa 与 Apollo 的集成:apollo-server-koa
Server 的入口
import { graphiqlKoa, graphqlKoa } from 'apollo-server-koa';import * as koa from 'koa';import * as koaBody from 'koa-bodyparser';import * as koaLogger from 'koa-logger';import * as koaRouter from 'koa-router';import { APP_NAME, APP_PORT } from './config';import { Schema } from './schema';import { Logger } from './utils';
const app = new koa();
app.use(koaBody());app.use(koaLogger());
const _router = new koaRouter();
_router.get('/graphql', graphqlKoa({ schema: Schema }));_router.post('/graphql', koaBody(), graphqlKoa({ schema: Schema }));_router.get('/graphiql', graphiqlKoa({ endpointURL: '/graphql' }));
app.use(_router.routes());app.use(_router.allowedMethods());
app.listen(APP_PORT, () => Logger.log(`${APP_NAME} running at ${APP_PORT} ports.`));Resolver 编写
Resolver 包含了从后端微服务中获取数据/转换/过滤等逻辑,在这里使用 gRPC 以 proto3 约定在 Server 进行注册并与微服务交互。
- GraphQL is in charge of setting up a contract with the outside world, while gRPC is in charge of communication between micro-services within the company.
例如常见的获取 branchList 的 resolver
resolvers/branchList.ts
import BranchClient from '@services/branch';
const client = BranchClient();
interface Params { branchName: string;}
export default (root: Root, params: Params) => { return new Promise((resolve: Resolve, reject: Reject) => { client.branchList(params, function (err: errorData, response: Response) { if (err) { return reject(err); }
// do anything... resolve(response); }); });};@services/branch.ts
import fs from 'fs';import * as grpc from 'grpc';import * as protoLoader from '@grpc/proto-loader';
const proto = protoLoader.loadSync(__dirname + '/branch.proto');
const BranchServiceClient = grpc.loadPackageDefinition(proto).branch.branchService;
export default () => new BranchServiceClient();Schema 编写
以往常见的使用 graphql 编写 Schema 类似于这样
schema.graphql
import { graphql, GraphQLSchema, GraphQLObjectType, GraphQLString,} from 'graphql';
new GraphQLSchema({ query: new GraphQLObjectType({ name: 'RootQuery', fields: { defaultBranch: { type: GraphQLString, resolve() { // do anything return 'main'; }, }, }, }),});在经历项目复杂,查询 fields 层级嵌套会很深,不利于解耦 query 与 resolver
这里利用 graphql-tools 来 parse schema 中 query 与 resolver 的对应关系,生成上述 schema
// schema.graphqltype Query { branchList(page: Int limit: Int): Branch}
schema { query: Query // mutation: Mutation}graphql/index.ts
- Apollo Server 现在内置了 graphql-tools
import * as path from 'path';import * as fs from 'fs';import { makeExecutableSchema } from 'apollo-server';import resolvers from './resolvers';const schemaPublic: string = fs .readFileSync(path.resolve(__dirname, './schema/schema.graphql')) .toString('utf8');
export const schema: any = makeExecutableSchema({ resolvers, typeDefs: [schemaPublic],});客户端接入 Client Access
理论上支持 GraphQL 的 request 库都可以满足,但我们想对前端 DX 再添加些能力
Apollo ClientSWRreact-query
以上三者都能覆盖我们当前的前端场景,但 Apollo 相比于 SWR 与 react-query 多出 20KB 左右的 bundle size,其中多出来的大部分功能在我们的业务场景下可能都不需要
而采用 stale-while-revalidate 思想的 SWR 与 react-query 提供了更多能切实提供前端 DX 的能力,以及支持 fallback 到 RESTful 的能力
- Caching mechanism
- Window Focus Refetching
- API for refetching queries
- Lazy queries
- Error handling
- 更好的 DevTool 状态显示
详细的 comparison
具体的接入例子不再列举,和常见更改 fetch 库的方式基本一致。
这里我们为了在 Client 得到与在 Server 端一致的类型定义,可以利用 graphql-codegen 根据 Server 定义好的 Schema 生成对应的 TypeScript typings
BFF 可能会出现的坏情况
待详细补充
- 多个 BFF 可能会出现重复代码
- 趋向于 ESB:BFF 中编写了过多业务能力的逻辑
- 性能问题:调用十几个 API 来拼装数据,以及转发多次的情况
More
部署
监控/可用性
鉴权
缓存
Why not Relay
总结
在当前大型项目的后端微服务化和前端微服务化的架构发展中,其实核心是围绕 关注点分离(Separation Of Concerns) 的思想,架构的各个环节的 Pattern 也被讨论出来,BBF 既有助于解耦 Microservice, 也有助于前端更专注于提升 UX,以及更大的自主权对于 API 和 数据格式 的定义,更快的适应未来的变化和需求,而 FE Engineer 的责任和边界也对应更加扩大。当然 BFF 也不属于一个完美的通用解决方案,服务于具体业务才是最重要的,本文只是提供一个思路,以及一些基本的架构设计。